

If you’ve walked outside in the past week and bumped into a person nose deep into their phone, they were probably playing pokemon go. As a child of the 90s I have fond memories of red and blue version and the endless hours spent playing them. Naturally, I picked up pokemon go immediately.
For those of you living under various rocks, pokemon go is a mobile game which makes you explore area around you to catch virtual pokemon. In order to catch pokemon you require a pokeball, These can either be bought with real money or you can receive them at various landmarks called “pokestops.” These “pokestops” are littered around cities and towns. The premise is simple, you walk around your town stopping at these landmarks and gain supplies.
This is ripe for optimization.
Luckily for us trainers this problem has already been explored, only in another form. The travelling salesman problem is a key problem in optimization. The travelling salesman classically had a person travel through a set amount of cities trying to minimize the distance she traveled while still visiting every city. This problem is computationally very tough to solve. Many algorithms have been written and tested to facilitate solving this problem.
The one i focused on is a genetic algorithm. Genetic algorithms mimic natural selection in order to find an optimal route. In my search I found a great blog post on optimal waldo search methods that uses a genetic algorithm. Here you can see Randal S Olson using it to solve a version of the travelling salesman problem involving Where’s Waldo. Naturally I wanted to apply it to my pokestops.
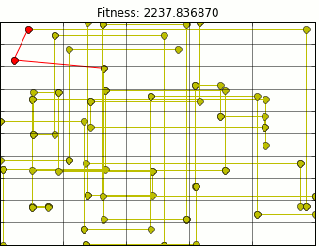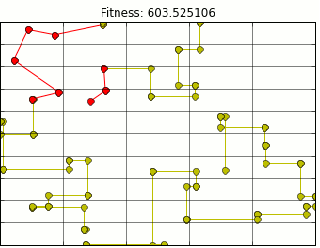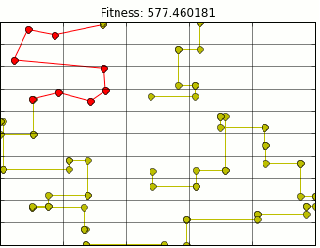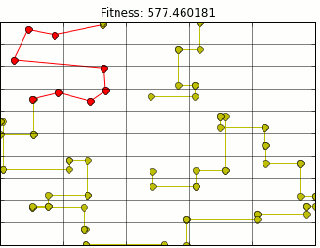
Using Mr. Olson’s Code and extracting all pokestop location data from Ingress (pokemon go precursor) provided me with the following path animation.
Quick note here, this is not the most optimal path, but it is close. Due to the nature of genetic algorithms we will get a close estimate. There are a few problems with the above path. First most glaring problem is that It assumes we can walk through buildings. I am not a haunter, so this is outta the question.
Luckily, I live in a city which utilizes the grid system of road planning. Because of that I can use taxi cab distance to approximate walking on a grid. However, in the upper left hand corner of the map above is a park with a good deal of pokestops. In the park area. In a park, I shouldn’t be constrained by buildings so I could walk on diagonals. I modified the code to calculate euclidean distance for park stops and taxi distance for everything else.

There is still something wrong. As you can see above, we are still moving through buildings, but now at right angles. Figuring out when/how to route around corners and up and down streets is a little more of a project than I am ready to tackle. So lets let google do that for us. Tapping into the google maps api distances are calculated for us using the correct routing. Our final map looks like this (plotting shows route through buildings, however distance is correct).

I guess I know which route I am going to be taking from now on.
Big shout out to Mr. Olson who wrote the underlying genetic algorithm code and part of the google maps api code I used. His write up on the waldo search is excellent and clear I highly suggest reading it.
As for next steps, there is something that is bothering me when I look at the above pathing, well a few things.
- It is not a closed loop: I will have to walk allllllll the way back home from where ever this route lets me off. We need to add a constraint that the last stop has to be the same as the first.
- Will my bag be full at the end of this?: I dont wanna waste time walking to more pokestops if i can’t receive any more supplies.
- I don’t have to visit all the pokestops/ pokestops recharge: This is the most important one. Unlike the travelling salesman, i do not have to visit everyone. I can stay in a small subsection and just repeatedly go the the same 3 stops if i wanted to.
These are some important caveats to the map. We’ll see if we can solve them next time on pokemon.
-Marcello







 As you can see the method is flying back and forth past our minima. However, the method eventually converges at (0.9987, 0.4987), our target minima. Below I have included a matrix containing our initial step and all of the following steps (taken from matlab output).
As you can see the method is flying back and forth past our minima. However, the method eventually converges at (0.9987, 0.4987), our target minima. Below I have included a matrix containing our initial step and all of the following steps (taken from matlab output).




 We now take the inverse of the Hessian and then find our next point. The iterative equation is listed below as well as the output.
We now take the inverse of the Hessian and then find our next point. The iterative equation is listed below as well as the output.


 This looks awfully like our iterative steps from our one dimensional Newton’s method. . As we get closer to our minimum the gradient, g, of our function moves toward 0 which makes xk≈ xk+1. This is when we know our method has found a minimum (hopefully). Hopefully this all feels familiar. Next post we will see how Newton Raphson works.-Marcello
This looks awfully like our iterative steps from our one dimensional Newton’s method. . As we get closer to our minimum the gradient, g, of our function moves toward 0 which makes xk≈ xk+1. This is when we know our method has found a minimum (hopefully). Hopefully this all feels familiar. Next post we will see how Newton Raphson works.-Marcello
 From this point we must calculate the gradient. I have taken the gradient of our function (f(x,y) = x^2 -x+cos(y+x)+y^2). This gradient must now be evaluated at our point (8,8)
From this point we must calculate the gradient. I have taken the gradient of our function (f(x,y) = x^2 -x+cos(y+x)+y^2). This gradient must now be evaluated at our point (8,8)


 We have an infinite number of directions to move In but let’s choose four test cases. We will choose the gradient, the negative gradient, and two other directions. For our initial point lets choose (-6,8). This point lets use evaluate our gradient Mapping these directions (all with a step of 0.1 ) produces the following graph.
We have an infinite number of directions to move In but let’s choose four test cases. We will choose the gradient, the negative gradient, and two other directions. For our initial point lets choose (-6,8). This point lets use evaluate our gradient Mapping these directions (all with a step of 0.1 ) produces the following graph.
 So you probably realized where we were headed. Following the steps above we have determined our iterative step. Like our previous one-dimensional search methods, our gradient search method iterates the above equation until a tolerance condition is met. The method described above is called the Method of Steepest Descent or Gradient Descent. Next Post we will go over the method with a real example.-Marcello
So you probably realized where we were headed. Following the steps above we have determined our iterative step. Like our previous one-dimensional search methods, our gradient search method iterates the above equation until a tolerance condition is met. The method described above is called the Method of Steepest Descent or Gradient Descent. Next Post we will go over the method with a real example.-Marcello