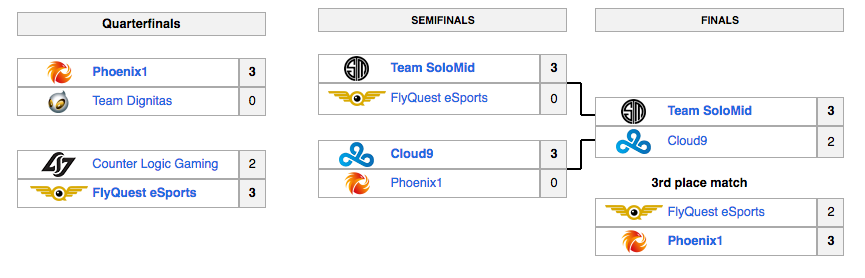
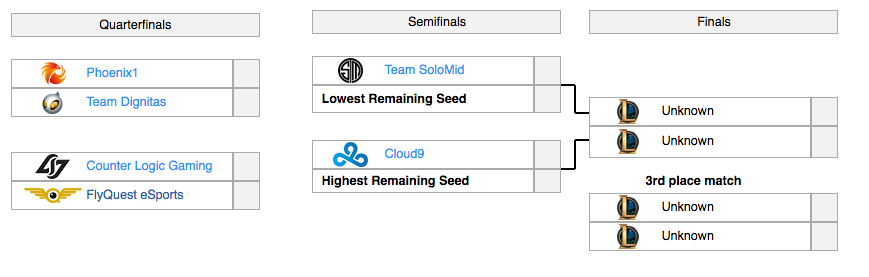
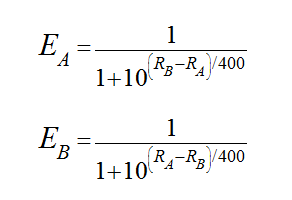Data is current up to: Spring Playoffs 2017My
previous post got me thinking. How does every team in that has ever participated in the North American League of Legends Championship Series (NALCS) stack up? For sports like chess, football, soccer, baseball, and many others an ELO based system is used to rank teams.Elo is a straightforward calculation and concept. If a team wins their rank should go up, if a team loses their rank should go down. How much these teams rise or fall is based upon their expectation of winning the game. A team that is mathematically favorited to win a game will rise slowly, but fall sharply if they lose. Conversely, a team that is not favored to win will fall slowly, but in the case of an upset will rise sharply. Using this concept, pioneered in sports of all types by
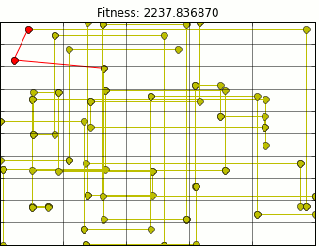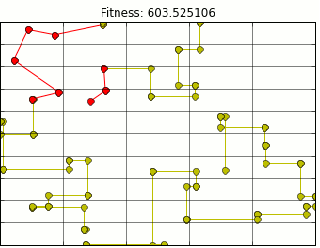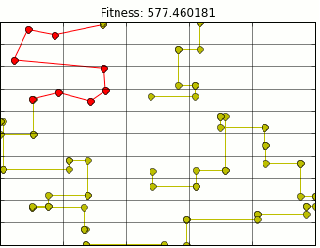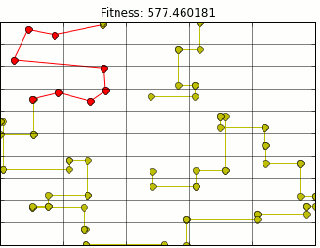
538, and applying it to League of Legends an online-only video game gives us insight into the …ahem … league.Inspired by the fantastic visualization 538 did with their
“Complete History of the NBA”, I set out to build a similar visualization for the NALCS. First, as all these projects go, I needed data. Unfortunately for me, there was no ready made database with all the info I needed. My first priority was to put together a database with W’s, L’s, and teams. League of Legends has a massive following and because of this has pretty good records.
Leaguepedia provided me with all the information I needed. I scraped all their NALCS match data, tidied it up, and built my database. This became the backbone for my ELO calculation.Calculating Elo is a simple process. I outlined it in
my last post which is worth a read. Once all elo’s were calculated I started building my visualization. The above visualization was made in D3.js. I started by using
Nate Miller’s block and then modified it like crazy to make it do everything I needed. The visualization starts with the Spring 2013 split. If you are familiar with LoL, this is actually the 3rd year in the championship season, but the first officially recognized by Riot Games the maker of LoL. This felt like a natural place to start. Here are a few interesting teams from the history of the NALCS.TEAM SOLO MID: THE BEST TEAM THE NALCS HAS EVER SEEN

Team SoloMid (TSM) has been around as long as competitive League of Legends has existed. They have participated in every single season and almost every single playoff. They are a force to be reckoned with. Ending the Summer 2016 split with a 17-1 record and a decisive playoff title, TSM cemented themselves as the greatest team in the the history of NALCS.CLOUD 9: A GAME AWAY FROM GREATNESS

Every great team has a great rival. Baseball had Yankees/Red Sox, League of Legends has TSM/Cloud 9 (C9). Cloud 9 only started one season after TSM, but quickly rose to be the best team the NALCS had seen. However after a string of losses, C9 began their fall. C9’s top position was taken by one game 3 years later by TSM.TEAM COAST: THE WORST TEAM THE NALCS HAS EVER SEEN

If TSM represents the best NALCS has to offer, Team Coast is the worst. Originally known as Good Game University (seen above in red), changed their name to Team Coast on June 1,2013. Coast never had a good record. The final nail in the coffin was Spring split 2015 where team Coast achieved an embarrassing 1-17 record, one of the worst records NALCS has seen.DIGNITAS: MOST DECIDEDLY AVERAGE TEAM

Now this one hurt. I have been a Dignitas fan since the early days of imaqtpie. Time and the NALCS has not been kind to Dig. They are one of the original LoL teams but they cannot seem to escape mediocrity. Their elo never swung more than 80 points outside average, even though they lost their spot in the NALCS in Summer 2016.ECHOFOX: TEAM OF MANY NAMES

In League teams rarely vanish completely, most get acquired, absorbed, or renamed. Echo Fox went through three name changes throughout their professional run. Originally Echo Fox was Curse Academy the challenger (think semi-pro) arm of the Curse brand. Curse Academy itself was a renaming of “Children of IWDominate”. They renamed after qualifying for Season three of the challenger league. Curse Academy rebranded themselves to Gravity Gaming after Riot’s new sponsorship rules involving the Curse voice chat client and their team by the same name. Finally on December 18th, 2015, Gravity Gaming was bought by Rick Fox of NBA fame and renamed to Echo Fox. The name changes have not helped their Elo.IMMORTALS: FROM HUMBLE BEGINNINGS

As a relative newcomer to the NALCS, Immortals have done well for themselves. Originally Team 8, Immortals have surpassed an exceed T8’s skill. T8 was a mediocre team, not straying far from average. However, with a new name, and more importantly a new roster, Immortals reached a peak elo of 1760, before taking 3rd place in the 2016 Summer split.